File Systems Unfit as Distributed Storage Backends : Lessons From 10 Years of Ceph Evolution
文件系统(本地)不适合做分布式存储后端:Ceph演变10年的经验教训
最近读了一篇关于Ceph后端BlueStore的论文,该论文发表在SOSP’19的会议上。讲了ceph分布式文件系统的存储后端的不断演变的经验教训,主要在这里做一个论文笔记。
Abstract
在过去的10年中,Ceph遵循了传统的本地文件系统作为Ceph分布式文件系统的后端。应为传统的文件系统久经沙场,非常的成熟。但是也带了了一些问题,最主要的有
- 构建0开销的事务处理机制很难
- 在本地级别的元数据性能会显著地影响整个分布式文件系统
- 对新兴的存储设备文件系统的支持非常缓慢
针对这些问题,Ceph卡法了BlueStore,一个直接针对裸盘的后端。仅仅诞生了2年,但是有70%的用户所承认。因为其运行在用户态并完全控制I/O栈,所以能使元数据空间利用率很高并且做到数据校验,快速覆写纠删码,内联压缩,减少一系列本地文件系统带来的性能陷阱。
BackGround
Ceph 文件系统的架构如下图所示:
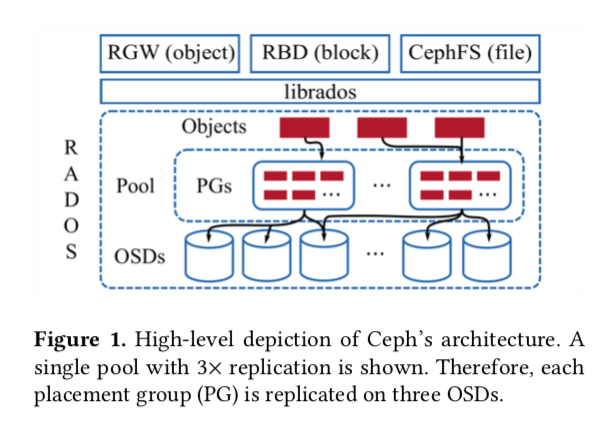
其中RADOS(Reliable Autonomic Distributed Object)是Ceph的核心系统。librados提供了转换和操控的接口。为上层提供对象,块和文件系统服务。
RADOS的逻辑组成使是由pools组成。每一个pool是PGs的单元组成,映射到各个OSD上。映射的方法使使用伪随机算法CRUSH。
在本地文件系统构建存储后端很困难
挑战1 高效事务处理
本地文件系统作为后端有三种方法
3.1.1 利用文件系统内部的事务处理方式 有一些文件系统使没有自带事务处理的,因为没有必要在一个本地文件系统上去确保内部之一。 Btrfs给用户提供两个系统调用。FileStore开始就使这么使用的,但是常常会出问题,比如遇到软件crash或者kill命令。这样Btrfs就无法保证存储后端是一个一致的状态。通过快照回滚的开销也很大,Btrfs最近也放弃了事务型系统调用。微软也尝试使用NTFS的内核事务框架提供原子文件事务API,但是最终因为高准入门槛而放弃了。
3.1.2 在用户态使用WAL 在用户态实现WAL(Wirte-Ahead Log)。这种方法存在三种问题
- RMW(read-modify-write 先读旧数据,与新数据一起合并写) 非常慢,事务要序列化然后写日志。还要调用fsync落盘,最后要应用到文件系统中。
- 非等幂操作 1⃣️ clone a→b; 2⃣️ update a; 3⃣️ update c。如果在第二步后crash那么WAL会修复b。在1⃣️ update b; 2⃣️ rename b→c; 3⃣️ rename a→b; 4⃣️ update d这个事务操作中,遇到在第3步后crash的话,WAL回复就会在update b时找不到b。
- 双写 在本地操作中会遇到I/O放大的情况。
3.1.3 使用K-V存储做为WAL
首先用户态的WAL的问题可以避免。但是RocksDB中存在的问题即日志文件系统会带来高一致性的开销。
挑战2 快速元数据操作
在ceph中需要做到经常的枚举本地文件系统的目录,而且遍历后的顺序使无序的。在RADOS中,由于使用文件的文件路径与文件名hash标示,还有一些scrubbing,recovery等操作,这些都需要枚举和排序。本地文件系统做这个比较慢。
挑战3 支持新的存储硬件
目前而言本地文件系统对于新型的存储硬件特性支持不是很好比如 SMR和ZNS 特性。
其他挑战
无法完全控制I/O栈,比如文件系统的页缓存,无法有效掌控SLO(service level objectives)。
BlueStore: 一个全新的方法
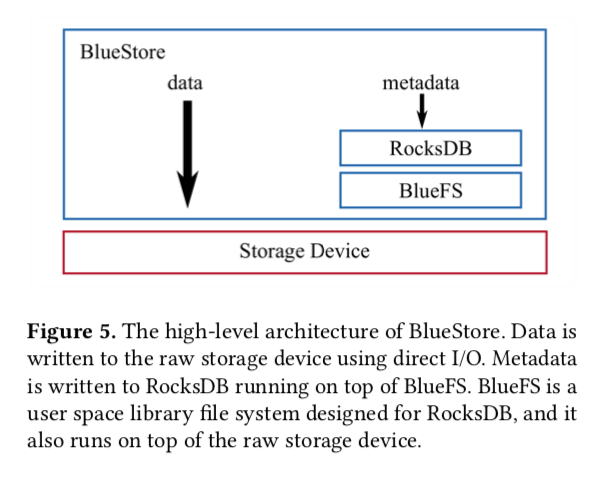
BlueStore一个精简了的文件系统,是POSIX I/O的子集,为RocksDB量身定做。在用户态,能够使用比较好的第三方库。可控的I/O栈,能够实现很多特性。
- 快速元数据操作
- 没有固定的对象写操作
- 实现COW操作
- 没有日志双写
- 为HDD和SSD优化I/O
BlueFS和RocksDB
下图是BlueStore的整体架构
下图是BlueFs在一个磁盘布局。metadata放在日志中,日志没有固定的位置。WAL LOG和SST都是RocksDB产生的文件。
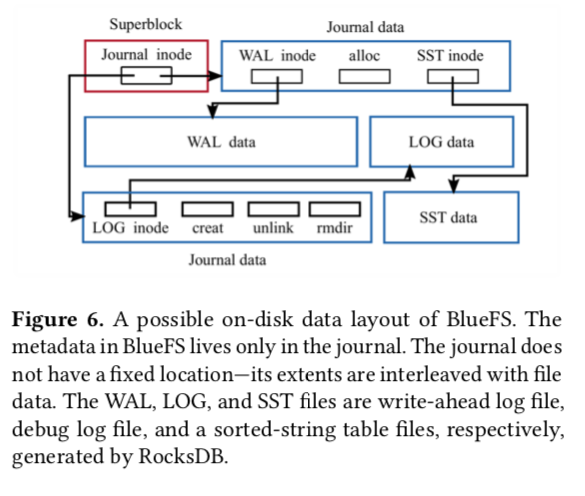
元数据的组织:在BlueFS中有多种命名空间 O for object 的命名空间 C for collect的元数据 B for block的元数据
路径与空间分配
BlueStore是一个提供COW的后端。这样做能够很好的做到高效clone,避免日志双写等。
采用ROW(Redirect on write)的方式,即数据需要覆盖写入时,将数据写到新的位置,然后更新元数据索引,这种方式由于不存在覆盖写,只需保证元数据更新的原子性即可。
比allocator默认大小小的数据写入,先存放在RocksDB中。可以批处理操作,根据设备的类型优化I/O
由于在用户态操作磁盘I/O,不能使用操作系统自带的页面cache。所以自己实现了Q2算法的一个cache。
BlueStore实现的特性
- 空间利用率高的校验码。每次操作都有。默认使用crc32c,cpu框架自带,效率高。而且根据类型的不同I/O做压缩校验。
- 实现覆写纠删码数据
- 透明的数据压缩
- 使用了SMR特性的接口
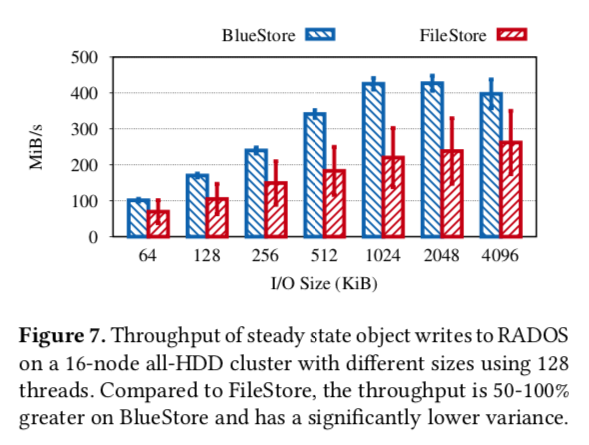
性能评估
就是BlueStore比FileStore牛逼太多
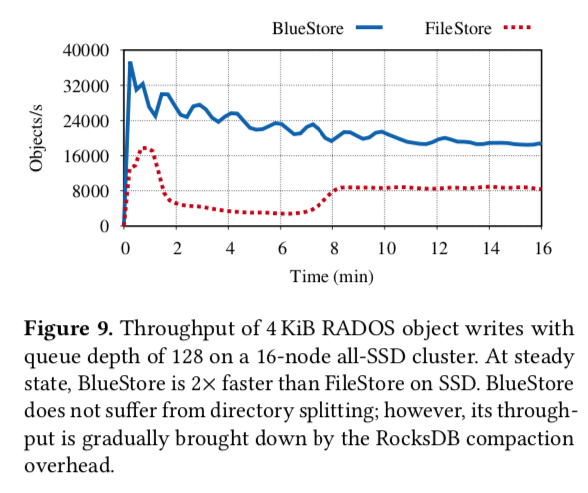
无论是吞吐:
 还是时延
还是时延
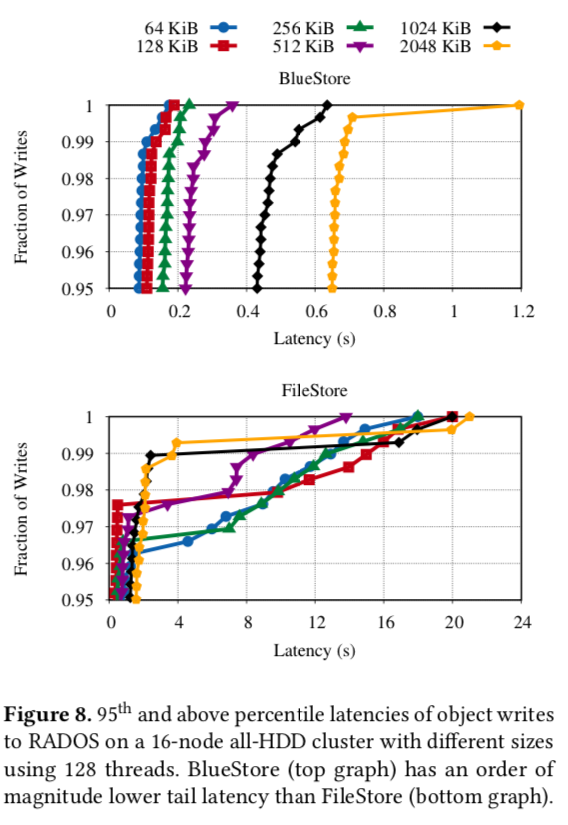 还是块存储性能
还是块存储性能
在裸盘上构建高效存储后端的挑战
缓存大小和回写
没有本地文件系统使用操作系统的缓存,由系统调度写入。而BlueStore需要自己去实现,而且要做到不能影响系统的性能。
kv存储效率
在使用NVMe中 RocksDB存在写放大,RocksDB自身数据序列化与拷贝是黑箱的,RocksDB自我特性导致性能抖动
高效利用CPU与内存
减少数据序列化与反序列化。使用SeaStar框架避免上下文切换导致的锁。
在读论文中还参考了
【1】https://zhuanlan.zhihu.com/p/45084771
【2】https://zhuanlan.zhihu.com/p/106096265
15 Apr 2020 by John Brown