raft只读操作优化
Raft 只读操作优化
为什么需要优化只读操作
raft是一个为分布式集群达成一致性的协议。对于集群需要保证一致性的数据,每次一操作其实都要确认此操作是否在集群中达成了一致。从是否会改变数据的角度,操作就分两个只读操作与写操作。只读操作顾名思义就是不会对数据做任何的改动。写操作包含了增删改等需要修改数据的操作,通俗说就是这次操作处理完后,数据有可能跟操作前不一样。
正是因为只读操作不对数据进行修改,所以raft可以优化只读操作。
-
因为只要客户端请求的是现集群真正的leader,那么获取到的数据就不会有错误。一个只读操作没有必要征求整个raft集群的共识。毕竟使用raft达成一个操作的共识还需要多节点网络请求与log持久化落磁盘等开销。
-
在恢复和安装快照,或者是raft集群加入新节点同步log与数据的时候,因为只读操作并没有改变数据,所以不需要还原这些操作也能保持数据的完整与一致,提高数据恢复的效率。
如何优化
优化只读操作的核心就是保证此时请求到该集群leader确实是能够向集群中法定人数的节点commit log成功。否则用户可能会读到陈旧的数据信息,无法保证线性一致。
用论文[1]中的话说就是
- leader必须拥有最新被提交的日志的信息
- 在处理只读请求前,leader必须确认自己是否已经被替换掉了
围绕这一核心目标,raft的作者在他PhD论文中提到了两种优化的方法。[2]
一. 使用readIndex
- 使用commitIndex做为readIndex。这里需要注意⚠️:当一个leader刚被当选时,虽然他肯定拥有最完整的信息,但leader无法确认自己的commitIndex是最新的。所以这个leader必须发一个no-op的空白log。直到这个空白log被commit了,保证了commitIndex为最新的。再将最新的commitIndex做为readIndex。
- 发起一次心跳,当收集到这次心跳返回ack中的commitIndex >= readIndex 且 commitIndex达到法定人数时。确认leader拥有最新被提交的日志且自己就是集群中的合法leader。
- leader的状态机至少执行到readIndex,保证线性一致性。
- 返回给状态机,执行这个只读的操作给客户。
readIndex这种方法,虽然避免不了网络请求的开销,但是减少了raft的log,也避免了读操作落磁盘的开销。
此方法实现以后,用户可以向follower请求只读操作,以保证负载均衡,增强系统读的吞吐率。这里需要注意,follower的数据可能落后当前leader很多,或者网络分区后跟随了错误的leader。所以,leader必须提供一个接口以返回当前的readIndex。follower请求这个接口,拿到当前的readIndex,然后leader执行1-2,被请求的follower在自己的状态机中执行3-4步。
但是我觉得这种负载均衡的方法并不是很巧妙。第一,增加了系统复杂度,第二,有了读放大。多了请求leader的网络操作。第三,这种方法并不能保证用户的写操作负载均衡。
现在系统一般使用对集群分组,对数据分片的方法来做负载均衡。这样既不会增加raft协议的复杂度,同时对读写操作都做了负载均衡。
二. 使用时钟(lease read)
方法二就是使用租期(lease)时间。在租期未过期时,在不进行任何网络请求下,保证用户只读请求。
首先还是要记录leader的commitIndex作为readIndex。但是不会专门发起一次心跳(一.中的2)。在租期不过期的情况下,保证leader的状态机至少执行到readIndex,给用户返回只读操作。
租期其实就是选举的时间差。当leader收到法定人数的心跳后,那么在raft系统设置超时选举(election timeout)这段时间内,自己的数据肯定是正确的。因为在这段时间里,肯定不会有新的leader产生。
这里使用论文[2]中的一副图来说明情况
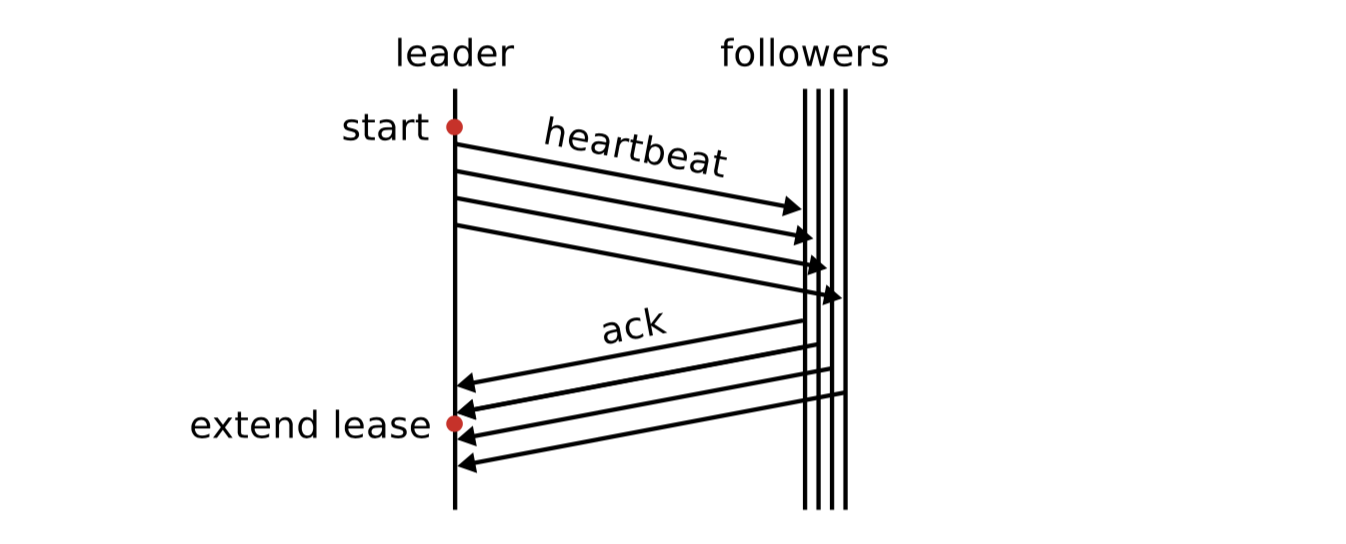
因为要考虑到进程调度,垃圾回收,虚拟机迁移,时钟频率不同等种种原因,需要设置一个bound(bound是大于1的)。其中start为leader向集群follower发送心跳的时间点。那么租期为: \(lease\_time = \frac{election\ timeout}{clock\ drift\ bound}\) 当收到法定人数的心跳点后,延长一个租期(lease_time)。虽然使用lease这种方法减少了时钟开销,但是如果这里的bound设置与现实不符,或者出现时钟严重漂移等问题。仍会导致旧leader可能给客户返回陈旧数据。
作者在文章[2]中最后又提出了一种方法来避免这种情况。
服务器在返回apply日志时,把这个日志对应的index也一并返回给用户,用户把这个日志的index保存起来,客户将跟踪与他们所看到的结果相对应的最新索引,并在每次请求时将这些信息提供给服务端。如果服务端收到的客户端请求的index大于服务器最新的applied的日志的index,则服务器不会为该请求提供服务。
不过这个描述我没太看懂。。因为要保证所有客户端都能知道最新的applied 的index,感觉这种情况才能避免。
TiKV中提供了一种解决方案[3],有点像一和二的结合体。不同的是在每次写操作时,进行租期的续约。如果长时间没有写操作,租期过期时,使用方法一(readIndex)进行。
[1] Ongaro D, Ousterhout J. In search of an understandable consensus algorithm (extended version)[J]. 2013.
[2] Ongaro D. Consensus: Bridging theory and practice[D]. Stanford University, 2014.
[3] https://pingcap.com/blog-cn/lease-read/
08 Feb 2020 by John Brown