Raft的go语言实现与使用(2017-6.824 Lab2-Lab3)
Raft协议的解读已经有很多,整体最主要的协议其实用论文中的两幅图就能大致表述了。最后再加上一个Snapshot的图解析基本就全。相对与Paxos而言,我个人认为Raft从实现协议的角度来说反而比Paxos要复杂。主要就是在于index的处理上。这此使用Go语言实现了一个Raft协议并支持snapshot。并且使用Raft协议实现了一个分布式的kv存储。
Raft的实现
Raft的成员变量
type Raft struct {
mu sync.Mutex // 锁
peers []*labrpc.ClientEnd // 所用成员的通讯信息
persister *Persister // 持久化信息
me int // 本节点在成员通讯信息的idx
//Persistent state on all servers
CurrentTerm int // 目前的Term,初始值为0
VotedFor int // 当前我投票给了谁
Log []LogEntry //log信息
// Volatile state
CommitIndex int // 目前确定提交的log的idx
lastApplied int // index of highest log entry applied to state machine init 0
// Only for leader
nextIndex map[int]int //for each server, index of the next long entry to that server
matchIndex map[int]int // for each server, index of highest long entry known to be replicated on server
ChanCharacter chan int //节点改变时的通知chan
Character int //当前本节点在Raft中的角色
TimeRest *SaftyTimeOut //定时器
ApplyMsgChan chan ApplyMsg //传输应用的信息的chan
PrevSnapIndex int //有快照时,快照保存的最近的idx
PrevSnapTerm int //有快照时,快照保存的最近的idx的Term
}
//与外界传输信息的结构
type ApplyMsg struct {
Index int
Command interface{}
UseSnapshot bool
Snapshot []byte
}
//log中包含的信息 Command中包含着需要达成一致的东西
type LogEntry struct {
Term int
Index int
Command interface{}
}
首先Raft对外提供的接口
-
对外接口
func (rf *Raft) GetState() (int, bool) {/*...*/}返回当前的Term和这个服务器是不是Leader(自己认为自己是否是Leader)
func (rf *Raft) Start(command interface{}) (int, int, bool){/*...*/}输入参数为需要达成一致的日志内容,返回日志的index,当前term和是否是leader(自己认为的)。
applyCh chan ApplyMsg一个对外提供已达成协议的管道。如果某项日志在成员之中通过了,那么就通过此通道告诉使用方。
-
对内的服务接口
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply){/*...*/}接口
AppendEntries主要作用是Leader向Follower添加Entry到Follower的日志当中,或者发送心跳包。在返回的reply中,Follower需要返回的当前的Term,出否成功等信息。type AppendEntriesArgs struct { Term int //current Term LeaderID int // LeaderID PreLogIndex int //index of log entry immediately preceding new ones PreLogTerm int //term of prevLogIndex entry LogEntries []LogEntry //log entries to store, request is heart beat if it's empty LeaderCommit int //leader’s CommitIndex } type AppendEntriesReply struct { Term int //currentTerm, for leader to update itself Success bool //return true if follower contained entry matching prevLogIndex and prevLogTerm isOk bool // rpc is ok ConflictIndex int ConflictTerm int }发送方(Leader):
- 如果(
nextIndex[FollowerID]已经没有新的日志需要传递了,args.LogEntries 置为空,否则传送从index从nextIndex[FollowerID]到自己最近的Log) - LeaderCommit置为目前已经达成一致的日志的Index(commitIndex)。
接收方(Follower):
- 如果当前currentTerm > Term, 返回false。如果currentTerm < Term,将自己的currentTerm置为Term
- 刷新定时器
- 如果日志中preLogIndex的Term与PreLogTerm不一样,Success为false(
if Log[preLogIndex].Term == PreLogTerm) - 如果已存在的日志与新来的这条冲突(相同的index不同的term),删除现有的entry,按照leader发送过来为准
- 将所有新的日志项都追加到自己的日志中
- LeaderCommit > commitIndex,将commitIndex = min(leaderCommit, 最新日志项index)
发送方(Leader):
- 如果返回的Term > currentTerm, 将自己的角色置为Follower, currentTerm置为Term。不在处理下面的流程。
- 如果Success为false,将这个Follower的nextIndex进行减一。如果为true,那么就把这个Follower的nextIndex值加(
nextIndex[FollowerID] += len(args.LogEntries)) - 达成一致后选取达成一致(quorum)的index置为commitIndex
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply){/*...*/}接口
RequestVote为Candidate向其他成员发起投票时当选Leader的接口。type RequestVoteArgs struct { Term int // candidate's term CandidateID int //candidate requesting vote LastLogIndex int //index of candidate LastLogTerm int //term of candidate's last log entry } type RequestVoteReply struct { Term int // currentTerm, for candidate to update itself VoteGranted bool // true means candidate received vote ok bool // rpc is ok }发送方(Candidate):
- 增加currentTerm
- 自己先投自己一票
- 重置计时器
- 向其他服务器发送RequestVote
接收方:
- 如果args.Term < currentTerm, 返回false
- 如果args.Term > currentTerm, currentTerm = args.Term,改变角色为Follower。如果
- 如果votedFor为空或者有candidateID,并且候选人的日志至少与接收者的日志一样新,投赞成票并刷新计时器。至少一样新是指:
args.LastLogIndex > my.LastLogIndex || (args.LastLogIndex == my.LastLogIndex && LastLogTerm >= Log[LastLogIndex].Term)发送方(Candidate):
- 如果收到的投票中term大于curTerm,curTerm = term,转变为Follower
- 如果投票RPC收到了来自多数服务器的票,当选leader。
- 如果收到了来自新Leader的AppendEntries RPC(term不小于curTerm),转变为follower
- 如果选举超时,开始新一轮的选举
- 如果(
Raft 日志的快速收敛
在工程实现中,会出现一种情况。就是当网络分裂时,形成了两个区域,一个含有新leader的区域,一个为老leader但不能达成法定人数的区域。如果持续有客户端项老leader的区域发送请求,虽然这些请求并不会达成一致性,但是,在老区域中的节点日志中会积累很多这样的未达成一致性的协议。如果网络愈合后,新leader在向老集群同步新日志时,如果一个一个使用递减index的方式区试时,会发现这种情况下会花费很长时间都不能找到合法的PreLogIndex。所以需要使用快速收敛,使其能够更快个同步日志。
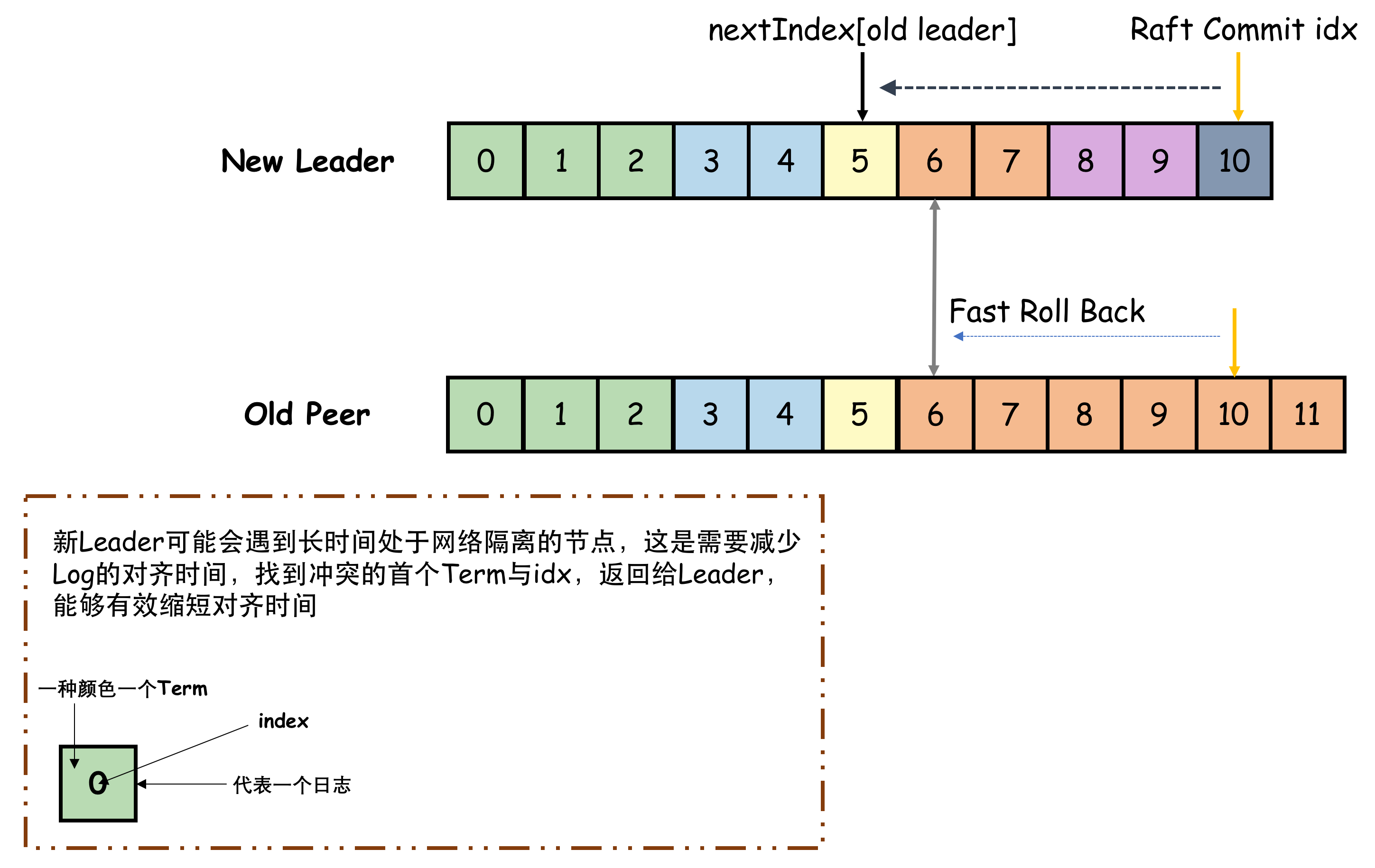 。
。
在论文中提到的方式是:
- 接收方在PreLogIndex不一致时,返回目前这个PreLogIndex这条日志的Term(ConflictTerm),并返回自己日志中这个第一次出现这个Term的index(ConflictIndex)。
- 发送方在自己的日志中找到这一个ConflictIndex,如果这条日志的Term与ConflictTerm相同,找到这个Term最后一个index(或者直接根据ConflictTerm寻找)。将这个–index作为下一次这个接收方PreLogIndex的传参。
这个方法主要就是利用了Quorum(抽屉原理),如果有新集群能够正常工作,那么其他非必然无法commit新日志。(我这里有一个想法:Old Peer可以返回自己最新的已commit的index,虽然可能会存在自己没有commit但是新集群已经被commit的日志,但是这些日志应该不会太多,这样的话收敛协议比较简单)
Raft 一致性安全
Raft的安全性如论文中x图所示,在leader频繁更换时,即使Leader成功发送给Quorum数量的某个提议,但是在没有收到Quorum数量的commit的情况下。不能够告诉客户端这条日志已经被确认了。Raft作者的博士论文的图更清晰明确一些
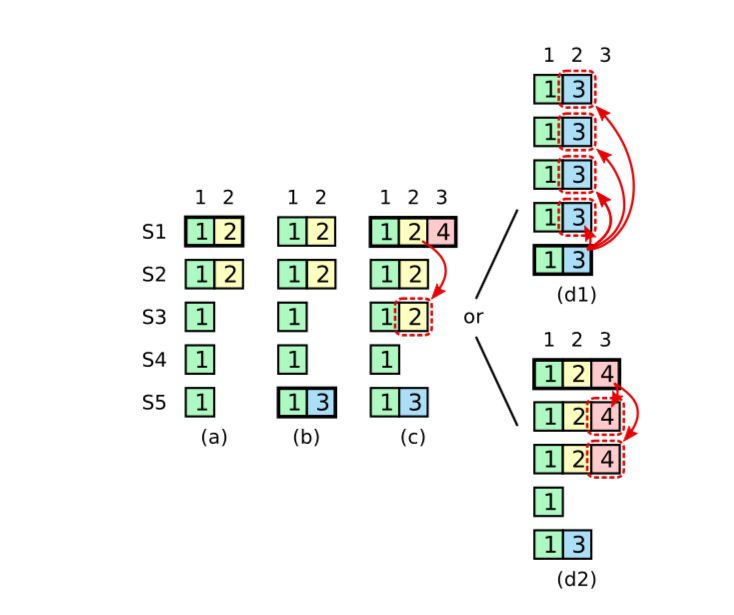 。
。
所以正确的确认方式应当遵循下图的逻辑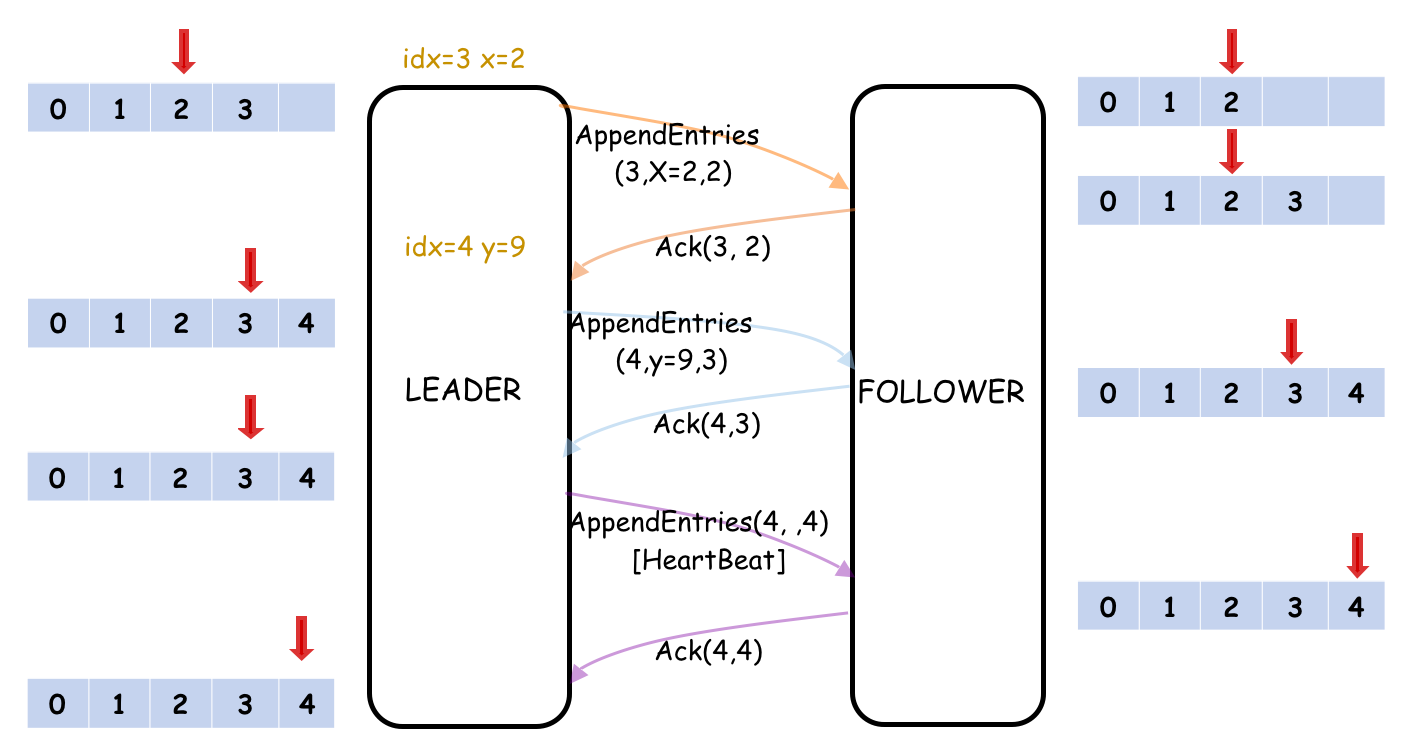
Raft 快照
快照就是当raft的日志很多时,造成空间浪费,因为之前很早已经达成一致性的日志已经没有必要存在了。这时需要使用快照的策略对用户的状态进行保存,并且抛弃已经给客户达成一致性的日志。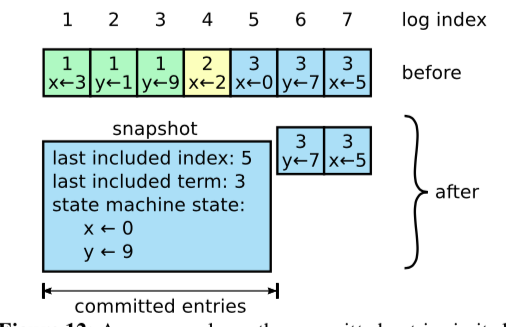
是否生成快照是由用户发起的,用户查看rf中log的大小,在超过指定的阈值后,每一个用户的阈值可以不同,那么他在何时需要生成快照也不同。快照唯一需要Leader操心的就是:当一个新raft成员加入到集群中,或者一个比较旧的raft成员重新加入到集群时,由于“欠账”太多时(Leader已经没有当时那个index的信息),需要Leader强行同步快照。
接口:
func (rf *Raft) ReadyToMakeSnapShot(index int) {/*...*/}
这个接口的主要目开始制作传入从这个index开始制作raft日志(这个index之后全部抛弃)
type InstallSnapShotReq struct {
Term int
Leader int
LastIncludedIndex int //快照中包含的最大Index
LastIncludedTerm int //快照中包含的最大Term
Offset int //唯一(多次传输使用)
Data []byte //数据
Done bool //是否已完成(多次传输使用)
SnapshotLog LogEntry //需要
}
type InstallSnapShotRsp struct {
CurTerm int //当前term
}
func (rf *Raft) InstallSnapShot(args *InstallSnapShotReq, rsp *InstallSnapShotRsp) {/*...*/}
InstallSnapShot 这一接口的目的就是Leader发送给“欠账太多”的Follower。让这个“落后”的Follower更快的”catch up”。
接受者:
- 如果args.Term > curTerm 立即返回rsp.CurTerm
- 如果自己不是Follower,变成为Follower
- 重制定时器
- 修改自己的PrevSnapIndex,PrevSnapTerm,CommitIndex
- 生成一个Msg,里边包括args.data 并在Msg中做一个UseSnapshot为True的标记
返回:
- 如果rsp.CurTerm > args.Term, 由Leader变为Follower,
- 否则将这个Follower的Next变为arg.LastIncludedIndex
使用Raft协议的分布式的KV存储
使用Raft做一个分布式KV存储(在这里称做kvraft)主要是为了更好的了解Raft的一些特性,即把Raft用起来。KV只要能保证是Raft的Quorum容灾和线性一致就可以。所以KV存储向外提供三个接口:Put(key, value), Append(key, arg), 和 Get(key)。服务为一个基本的KV数据库存储。Put将一个特定的Key放入数据库中,Append将arg中的值追加到键值中,Get获取当前key的值。如果遇到Append一个不存在的key,相当于Put操作。
具体的kvraft的逻辑如下图所示:
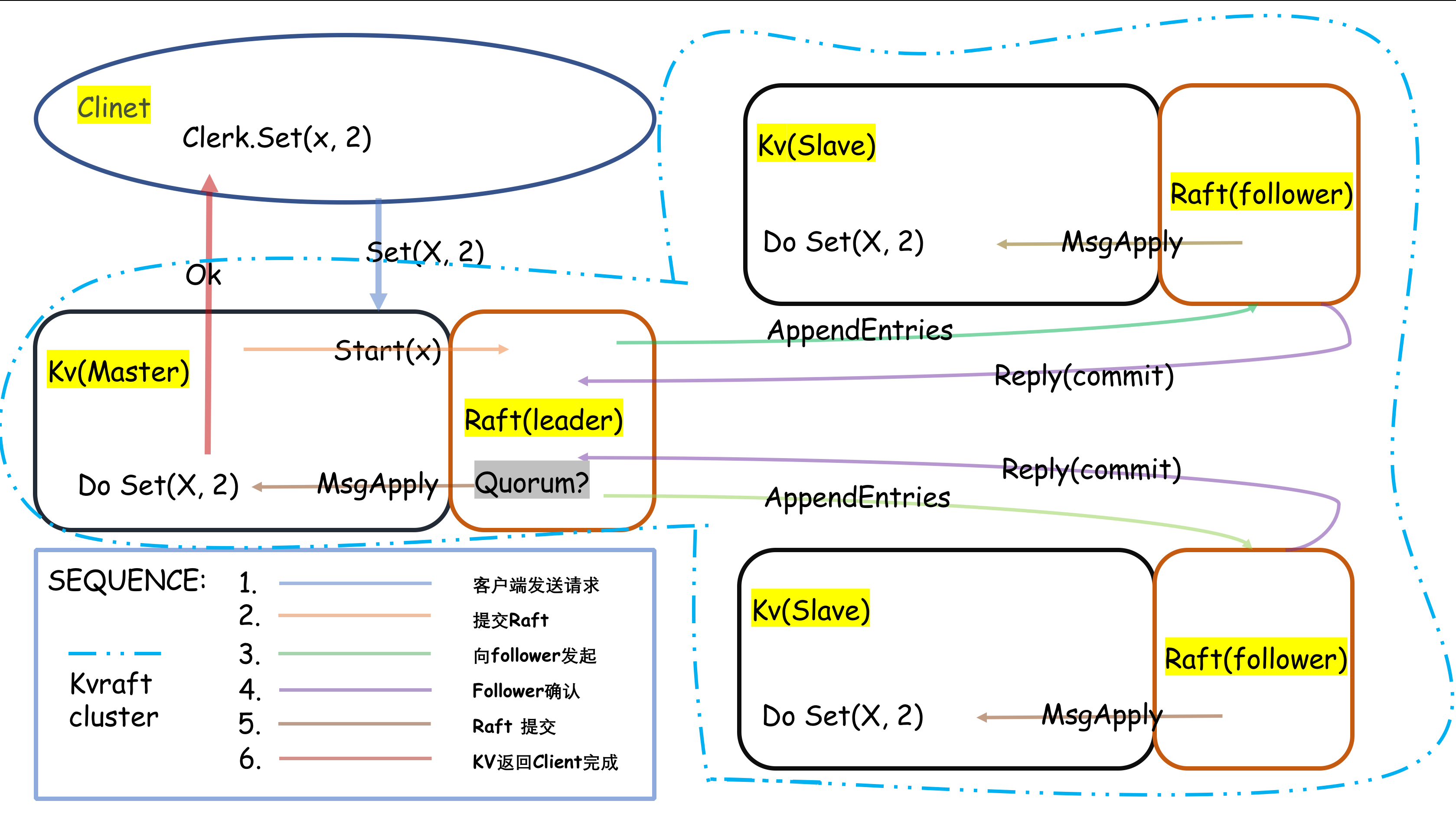
用户侧(Clerk)
首先用户侧使用Clerk进行操作,Clerk包含了三个接口Put(key, value), Append(key, arg), 和 Get(key),暴露给用户,用户使用类似与Clerk.Put(k,v)进行操作。之所以不直接调用KVraft服务的是因为Clerk做了以下操作:
- 为了防止重复请求,每一次请求需要有一个全局唯一且递增的序列号
- 由于序列号的原因,在没有请求服务成功之前是不会返回的
- 需要查找KVraft服务到底那台机器是Raft的Leader
func (ck *Clerk) OP(key string) string {
// You will have to modify this function.
var args GetArgs
var value string
args.Key = key
args.ID = ck.ID
ck.mu.Lock()
ck.Seq++
args.Seq = ck.Seq
ck.mu.Unlock()
var reply GetReply
for {
ok := ck.servers[ck.leaderNo].Call("RaftKV.OP", &args, &reply)
if ok && !reply.WrongLeader && reply.Err != KVTimeOut {
if reply.Err == OK{
break
}
}
//something worry with network or leader change. retry other server
ck.mu.Lock()
ck.leaderNo = (ck.leaderNo + 1) % len(ck.servers)
ck.mu.Unlock()
}
return reply.value
}
服务侧(kvraft)
- 服务侧对外提供三个接口
Put(key, value),Append(key, arg), 和Get(key)。节点与节点之间使用通讯完全使用Raft协议进行“交流”(数据传输)。 - 服务器与每一个请求都需要经过Raft一致性协议的协商,包括Get请求。因为会出现如下状况
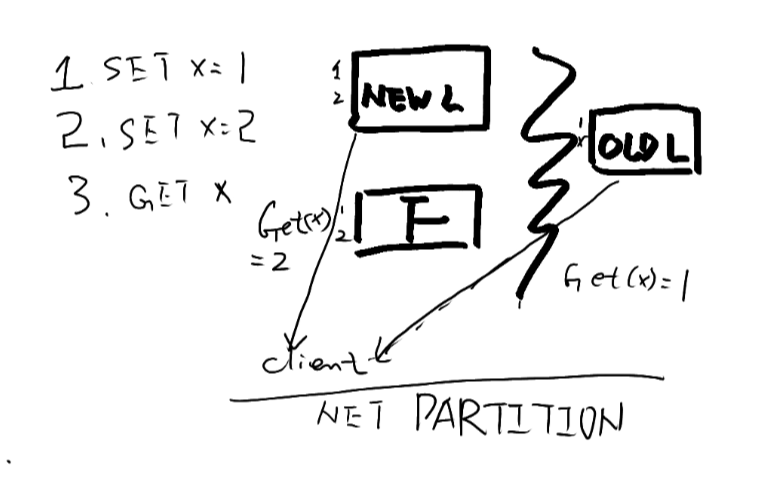 :当旧Leader被网络隔离时,结果会出现线性不一致。
:当旧Leader被网络隔离时,结果会出现线性不一致。 - 如果出现网络错误可能会造成重复提交,比如一个写操作,服务端已经写入,但是在返回给用户时出现了网络失败,用户无法收到写成功的返回,会重复这个操作,造成数据错误。所以服务器需要记录用户ID以及对应这个用户的最大请求Seq,以保证重复请求不会影响服务。
- Raft的Msg分为两种,一种为普通请求,一种为Raft的安装快照。
28 Sep 2019 by John Brown