6.824:Lab6-7 Replicated State Machine
Paxos
Introduction
在实验6-7中,将使用RSM(replicated state machine)的方法复写锁服务,在这个方法中,有一个节点为master,master接收来自client节点的请求并在所有的节点以相同的方式在所有的副本下执行。
当master节点失败,任何一个副本都会接管master的工作,因为这些副本都与那个失败的节点有着相同的状态。其中一个比较有挑战性任务时确保集群中的每一个节点所接受的信息是一致的(即哪些是副本,谁是master,哪些副本是keepalive的),即使存在网络分裂(network partition)或者是乱序的情况,数据仍然要保持一致。这里我们使用Paxos协议来实现这一策略。
在此次实验中,将要实现Paxos并使用达成集群成员的改变(view change)。
-
RSM module
RSM负责副本管理,当一个节点加入时,RSM模块直接配置并添加。RSM模块也是管理recovery线程确保在相同的view下每一个节点的状态是相同。这个本实验中唯一需要recovery Paxos操作。在实验7中,RSM模块将管理锁服务。
-
config module
config模块负责管理view的改变。当RSM模块要求在当前view上添加一个节点时,config模块将使用Paxos来开启一个新view。config模块将周期性的发送心跳来检查集群中的其他节点是否存活,如果某一成员不需要失联,就讲此节点从当前的view中移除出去,移除节点也会使用paxos协议来达成一个新的view,这个view的value中移除了那个失联节点。
-
Paxos模块
Paxos模块负责运行Paxos协议来维持值一直。原则上这个值(value)可以是任何集群想要达成一直的value(当前成员节点,每一次操作的日志 etc.)。在我们的系统中,将value作为当前集群的节点成员。
Uderstanding how Paxos is used for view changes
Paxos的实现使用了两个类,acceptor与proposer。每一个副本都有这两个类。proposer类通过提出新value的方式来发起一个paxos协议,并发送给所有的副本。acceptor类处理来自proposer的请求,并作出反馈。proposer中的run方法获取现有的nodes值,并达成一个新的value值。当一个新的instance(epoch)完成时,acceptor将调用config的paxos_commit(instance, v)方法进行提交。具体流程如下列所示: 系统从头开始,第一个节点创建了view 1,仅仅包含了它自己,view_1 = {1}.({values})。当节点2加入时,两节点的RSM模块加入了1,并从节点1的中得到了view。然后,节点2要求它的config模块奖自己加入view1,config模块调用Paxos发起一个新的view:view_2 包含了节点1与2。当paxos成功之后 view_2为 view_2={1,2}。同理当节点3进入时,通过Paxos后view_3 = {1,2,3}。
Paxos Protocal
实验指导书上已经将propose和acceptor的具体框架写好。为代码如下:
proposer run(instance, v):
choose n, unique and higher than any n seen so far
send prepare(instance, n) to all servers including self
if oldinstance(instance, instance_value) from any node:
commit to the instance_value locally
else if prepare_ok(n_a, v_a) from majority:
v' = v_a with highest n_a; choose own v otherwise
send accept(instance, n, v') to all
if accept_ok(n) from majority:
send decided(instance, v') to all
acceptor state:
must persist across reboots
n_h (highest prepare seen)
instance_h, (highest instance accepted)
n_a, v_a (highest accept seen)
acceptor prepare(instance, n) handler:
if instance <= instance_h
reply oldinstance(instance, instance_value)
else if n > n_h
n_h = n
reply prepare_ok(n_a, v_a)
else
reply prepare_reject
acceptor accept(instance, n, v) handler:
if n >= n_h
n_a = n
v_a = v
reply accept_ok(n)
else
reply accept_reject
acceptor decide(instance, v) handler:
paxos_commit(instance, v)
其实这一实验的中心就是实验Paxos协议。propser和acceptor框架已经搭好,所需要做的就是将其成员函数补齐。伪代码已经给出,剩下的就是实现与调试。
Replicated State machine
Introduction
在这个实验中奖使用RSM(复制状态机)的方法实现锁服务的副本管理。在RSM方法里使用一主多备份(one master, others slaves)。master节点负责处理来自客户端(client)的请求并在都有副本上执行这些请求。为了保证所有副本完全一致,这些副本的执行顺序必须完全有序,所有请求的所有结果必须完全一致。RSM使用Paxos协议处理节点成员之间的变更(如失败和重新加入副本等)
为了确保所有的请求的顺序是唯一的,主节点给每一个请求分配一个viewstamp以保证序列。viewstamp又两个部分组成,一个为view number(paxos协议)和一个单调递增的序列号(seq no)。一般而言,viewstamp中的view number由高到低排序,seq no也是有高到低排序。怎样保证viewstamps是唯一的呢?这是因为Paxos保证左右的viewnumber是一个有序的。另外对于每一个view,现有的view成员是一致的,所以RSM节点可以保证一个唯一的master,只有它可以给每一个请求一个递增的seqno来保证在一个view中请求的顺序性。
这一实验的首要任务是在我们现有的RPC库之上构建一个RSM库,以确保副本的一致性。有一些约束的调节来确保所有副本以相同的顺序执行相同的请求得到相同的结果。一旦你已经构建好了RSM库,我们将要求你使用RSM对锁服务进行副本化。
Start
首先提供了rsm_client 与 rsm 这两个文件。RSM_clinet主要确定并与服务的master节点进行通信,lock_client可以使用call的方法调用RSM的这一方法(invoke)。
为了将所有的服务的副本化,你服务必须创建一个RSM服务对象,并使用他来处理来自客户端的RPC。并使用config对服务进行Paxos的一致性保障。
Your Job
你的工作是将锁缓存服务构建在RSM服务之上,通过rsm_test.pl 8-16进行测试。
Step One 副本化锁缓存服务
重构lab4中的锁缓存服务包括客户端与服务端(lock_server_cache_rsm 与 locker_client_cache_rsm)
在实现锁缓存服务副本化时应当考虑三个问题。
-
server端(SVR_HDL)不要直接去调用client端(SLT_HDL),会发生死锁(RSM层的invoke_mutex 死锁)。C_A向S请求acquire L1(申请了invoke_mutex),而这时L1在C_B上,S又向C_B发起revoke,但是上一步(acquire L1还未完成)S拿着invoke_mutex,这样会产生死锁。所以不可在调用中再调用。为了解决这个问题,使用多个线程进行处理。client使用 releaser 这个线程专门进行release处理,server使用revoker和retryer 对客户端进行revoke和retry调用。
以客户端为例,基本逻辑为利用rpc/fifo.h提供的队列,连接RPC handler和background(releaser etc.)线程之间的通信。fifo队列中一个pthread_cond_t,当队列为空的时候休眠,当队列有东西的时候被唤醒,有点像生产者和消费者模式。handler作为生产者将需要处理的item放入到队列中,releaser作为消费者,一旦在队列中存在item,就对此item进行处理。见下列代码:
//This is a producer void lock_client_cache_rsm::DealRelease(ClientLockRSM & lock_item, lock_protocol::lockid_t lid) { if (lock_item.status == AcqRet::NONE) { //primary done, req will resend, so this situation will happend //release_queue_.enq(&lock_item); return; } if (lock_item.is_revoked){ lock_item.status = AcqRet::RELEASING; release_queue_.enq(&lock_item); }else{ lock_item.status = AcqRet::FREE; lock_item.is_finished = true; } pthread_cond_broadcast(&lock_item.wait_free_); pthread_cond_broadcast(&lock_item.wait_acq_); }//This is a consumer void lock_client_cache_rsm::releaser() { // This method should be a continuous loop, waiting to be notified of // freed locks that have been revoked by the server, so that it can // send a release RPC. do{ ClientLockRSM * lock_item_ptr = NULL; release_queue_.deq(&lock_item_ptr); VERIFY(lock_item_ptr != NULL); pthread_mutex_lock(&lock_map_mutex_); lock_protocol::lockid_t lid = lock_item_ptr->lid; lock_protocol::xid_t xid_ = lock_item_ptr->xid; if (lu != NULL) lu->dorelease(lid); int r; pthread_mutex_unlock(&lock_map_mutex_); lock_protocol::status ret = rsmc->call(lock_protocol::release, lid, id, xid_, r); tprintf("I send it %llu back to server\n", lid); VERIFY(ret == lock_protocol::OK); pthread_mutex_lock(&lock_map_mutex_); lock_item_ptr->is_finished = false; lock_item_ptr->is_revoked = false; lock_item_ptr->status = AcqRet::NONE; pthread_cond_signal(&lock_item_ptr->wait_free_); pthread_mutex_unlock(&lock_map_mutex_); }while(true);同理在锁服务端还有一个revoker和retryer,与其类似。
-
缓冲锁服务的客户端应当有能力处理锁服务的失败,因为一旦primary(master)节点失败选出新的primary节点后,客户端是不清楚老的primary节点是否已经处理了自己的请求。
为了处理这一问题,客户端要给所有自己的请求一个系列号,此序列号非比序列号(非rsm viewstamp中的seqno),每一个请求有一个唯一的用户ID(这里其实用的就是与Lab4一样的IP端口号二元组),对于一个acquire请求,客户端选出一个未使用的seqno,并将其seqno作为参数参入到请求中。release同样需要将这个seqno传入。使用这一方法就需要客户端记住每一个锁每一个用户的最大seqno,这里我将锁结构加入一个map记录这一信息(lock_info_)
struct CondLockCacheRSM : public CondLock{ //Recode every user_id with it's highest std::map<std::string, lock_protocol::xid_t> lock_info_; std::queue<std::string> wait_retry_queue_; std::queue<std::string> wait_revoke_queue_; lock_protocol::lockid_t lid; std::string user_id; };服务端应该丢弃掉过时的请求,但是必须回复一个来自相同客户端重复信息的请求。 这里我们使用lock_protocol::lockid_t xid_t 作为seqno。
-
如果没在没有失败的情况下,所有服务起的所状态应当是一致的。如果要达到这一条件,必须要满足一下两点:
- 当input作用于所有的副本之上,且作用方式要相同,(才能得到相同的状态)
- 当input只有primary承担时,不应该改变primary的状态
换句话说就是primary与non-primary(master与slaves)之间的状态在没有失败的情况下应当是完全相同的。
在完成了次步骤后使用Lab1当时测试lock的locker_test应当要passed all tests sucessfully才可以
Setp Two:RSM Without Failures
第二步的任务是在第一步锁服务正常的情况下,使用RSM机制。
- RSM客户端通过调用invoke函数请求master节点
- master节点分配client请求一个viewstamp,然后将此请求再发送给每一个slave
- 如果次请求的viewstamp正常,slave将执行这个请求并返回OK给master
- master收到所有的slave都返回正常(
rsm_client_protocol::OK)后,在本地执行并将回复发送给客户端,如图[1]:
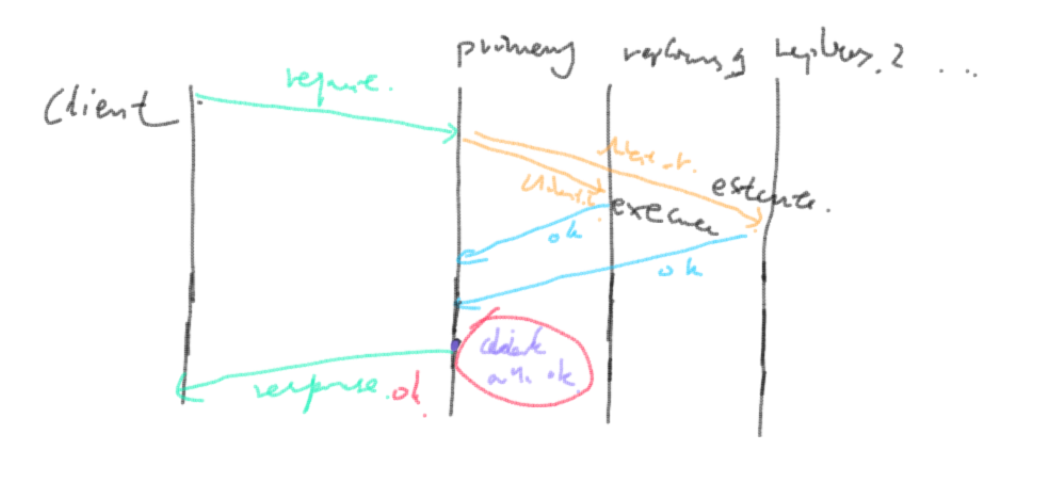
图[1] 副本化客户端请求服务端逻辑
具体的一些细节如下:
-
rsm::client_invoke中如果paxos的view正在改变,应当返回rsm_client_protocol::BUSY告诉客户端稍后重试,如果RSM已经不再是此集群的master节点,应当返回rsm_client_protocol::NOTPRIMARY,client会调用init_members(),重新选出一个master节点。如果一切正常,分配一个seqno,将自己的viewstamp和req发送给其他slave,(
cl->call(rsm_protocol::invoke, procno, last_myvs, req, dummy, rpcc::to(1000));)。确认所有slave都ok后,自己调用execute()。如果有一个slave返回不OK的时候(或者失败)的时候,master节点不执行此次请求,返回rsm_client_protocol::BUSY,此时失败的slave节点的seqno将与其他正常节点的不相同,导致其进行recovery(heardbeat失去联系,remove_wo)。如图[2]所示:
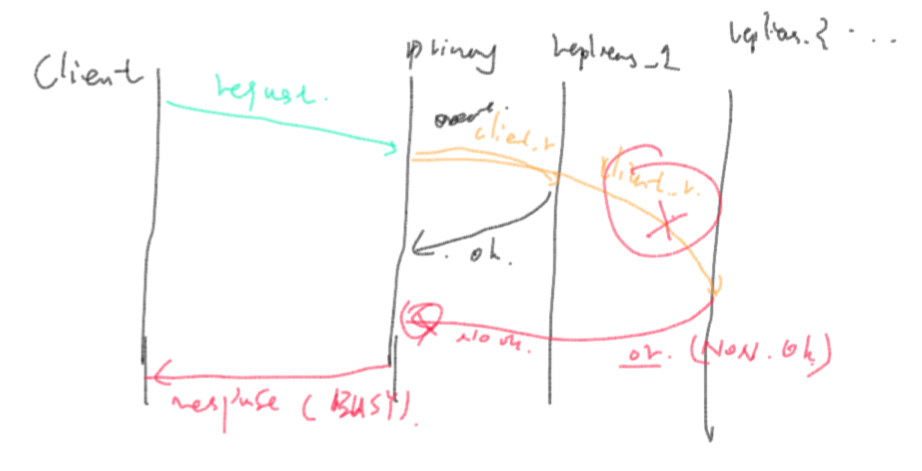 图[2] 有副本节点失败的
图[2] 有副本节点失败的具体代码如下:
rsm_client_protocol::status rsm::client_invoke(int procno, std::string req, std::string &r) { int ret = rsm_client_protocol::OK; // You fill this in for Lab 7 ScopedLock inv_m(&invoke_mutex); ScopedLock rsm_m(&rsm_mutex); if (inviewchange){ ret = rsm_client_protocol::BUSY; }else if (primary != cfg->myaddr()) { ret = rsm_client_protocol::NOTPRIMARY; } if (ret != rsm_client_protocol::OK) return ret; bool is_fail = false; last_myvs = myvs; myvs.seqno++; int index = 0; std::vector<std::string> view = cfg->get_view(vid_commit); for(typeof(view.begin()) it = view.begin(); it != view.end(); it++){ if (*it == primary) continue; int dummy; rsm_protocol::status rpc_r = rsm_protocol::ERR; handle h(*it); rpcc *cl = h.safebind(); pthread_mutex_unlock(&rsm_mutex); if (cl){ rpc_r = cl->call(rsm_protocol::invoke, procno, last_myvs, req, dummy, rpcc::to(1000)); } pthread_mutex_lock(&rsm_mutex); if (rpc_r != rsm_protocol::OK){ is_fail = true; tprintf("I am here is_false=true\n"); break; } if (index++ == 0){ breakpoint1(); partition1(); } } if (is_fail) return rsm_client_protocol::BUSY; execute(procno, req, r); return ret; }lock_tester中使用cache_rsm调用。
- 只有primary节点才与client节点通信,其余的副本slave节点对于retry和rovoke的行为保持沉默就好,
if (rsm->amiprimary())在retryer和revoker中加入判断,如果非primary就当作什么也没有发生,primarycall(rlock_protocol::retry, lid, xid, r);与客户端进行通行。 -
客户端与服务端进行通行的时候,不能直接使用lock_server在RPC上注册的函数,而要使用rsm_client的invoke于服务段rsm_server中的client_invoke通行,好在实验代码以提供了这样的函数并完成,只是在调用时注意。以请求客户端的acquire为例:
int lock_client_cache_rsm::SendAcqToSvr(ClientLockRSM & lock_item, lock_protocol::lockid_t lid){ int r; xid++; lock_item.is_retried = false; lock_item.xid = xid; pthread_mutex_unlock(&lock_map_mutex_); int ret = rsmc->call(lock_protocol::acquire, lid, id, xid ,r); pthread_mutex_lock(&lock_map_mutex_); tprintf("I sent a msg to svr, ret=%d, xid=%lld, ret=%d\n", r, xid, ret); if(ret != lock_protocol::OK) return ret; if (r == AcqRet::OK){ lock_item.status = AcqRet::FREE; tprintf("%s said OK lid:%lld\n", rsmc->primary.c_str(), lid); } else if (r == AcqRet::RETRY) { lock_item.status = AcqRet::ACQING; } else { tprintf("unknow svr return %d\n", ret); } return ret; }Step Three:Cope With Backup Failures and Implement State Transfer
这一步需要处理备份失败后。当发一线一个失败的节点或者是有一个新的节点加入时,这里就需要考虑Paxos协议。这些行为会调用commit_change()达成一个新的view,当新的view形成时,inviewchange为true,表明了这个节点在正常工作前需要通过RSM状态恢复(recovery)。recovery函数已实现。
所有的副本应当从master节点通过转移状态(transferstate)恢复。这个状态应当与primary的一模一样。当recovery结束时,将inviewchange值置为false,从而允许处理请求,在所有的副本恢复完成前,primary节点不应当接受与发送任何的请求给副本。
实现状态转移,最主要的是要实现marshal_state和unmarsh_state方法。(其实就是将primary那个装lock信息的map序列化后传给slave,然后slave再反序列化成自己的lock信息)这里可以使用rpc通信中的marshall和unmarshall类,« 已经重载很方便。
std::string
lock_server_cache_rsm::marshal_state()
{
marshall rep;
ScopeLock ml(&m_lock_mutex_);
rep << (unsigned int)map_lock_.size();
foreach(map_lock_, lock_it){
rep << lock_it->first;
rep << lock_it->second.is_locked;
rep << lock_it->second.lid;
//rep << map_it->second.pcond; pcond is not used after lab4
rep << lock_it->second.user_id;
rep << (unsigned int)lock_it->second.lock_info_.size();
foreach(lock_it->second.lock_info_, info_it){
rep << info_it->first;
rep << info_it->second;
}
std::queue<std::string> tmp_queue = lock_it->second.wait_retry_queue_;
rep << (unsigned int)tmp_queue.size();
while(!tmp_queue.empty()){
rep << tmp_queue.front();
tmp_queue.pop();
}
tmp_queue = lock_it->second.wait_revoke_queue_;
rep << (unsigned int)tmp_queue.size();
while(!tmp_queue.empty()){
rep << tmp_queue.front();
tmp_queue.pop();
}
}
return rep.str();
}
void
lock_server_cache_rsm::unmarshal_state(std::string state)
{
unmarshall rep(state);
ScopeLock ml(&m_lock_mutex_);
map_lock_.clear();
unsigned int lock_size = 0;
rep >> lock_size;
for(unsigned int i = 0; i < lock_size; i++){
lock_protocol::lockid_t lockid = 0;
rep >> lockid;
CondLockCacheRSM& lock_item = map_lock_[lockid];
rep >> lock_item.is_locked;
rep >> lock_item.lid;
rep >> lock_item.user_id;
unsigned int info_size = 0;
rep >> info_size;
std::map<std::string, lock_protocol::xid_t>& info_item = lock_item.lock_info_;
info_item.clear();
for(unsigned int j = 0; j < info_size; j++){
std::string key;
lock_protocol::xid_t value;
rep >> key;
rep >> value;
info_item[key] = value;
}
unsigned int retry_size = 0;
rep >> retry_size;
std::queue<std::string>& retry_queue = lock_item.wait_retry_queue_;
{
//clear the queue
std::queue<std::string> empty_queue;
std::swap(retry_queue, empty_queue);
}
for(unsigned int k = 0; k < retry_size; k++){
std::string item;
rep >> item;
retry_queue.push(item);
}
unsigned int revoke_size = 0;
rep >> revoke_size;
std::queue<std::string>& revoke_queue = lock_item.wait_revoke_queue_;
{
//clear the queue
std::queue<std::string> empty_queue;
std::swap(revoke_queue, empty_queue);
}
for(unsigned int l = 0; l < revoke_size; l++){
std::string item;
rep >> item;
revoke_queue.push(item);
}
}
}
之后需要同步状态时处理以下几个函数:
-
rsm::sync_with_backups //就是为了找出现在所有的backup,并等待他们全部recovery结束
bool rsm::sync_with_backups() { pthread_mutex_unlock(&rsm_mutex); { // Make sure that the state of lock_server_cache_rsm is stable during // synchronization; otherwise, the primary's state may be more recent // than replicas after the synchronization. ScopedLock ml(&invoke_mutex); // By acquiring and releasing the invoke_mutex once, we make sure that // the state of lock_server_cache_rsm will not be changed until all // replicas are synchronized. The reason is that client_invoke arrives // after this point of time will see inviewchange == true, and returns // BUSY. } pthread_mutex_lock(&rsm_mutex); // Start accepting synchronization request (statetransferreq) now! insync = true; // You fill this in for Lab 7 // Wait until // - all backups in view vid_insync are synchronized // - or there is a committed viewchange backups = cfg->get_view(vid_insync); for(typeof(backups.begin()) it = backups.begin(); it != backups.end(); ){ if (*it == primary) it = backups.erase(it); else it++; } while(vid_insync == vid_commit && !backups.empty()) pthread_cond_wait(&recovery_cond, &rsm_mutex); insync = false; return true; } - rsm::sync_with_primary // slave节点,调用statetransfer进行状态转移(从primary那里marsh lock map,再unmarshall到自己的lock map 中)
bool rsm::sync_with_primary() { // Remember the primary of vid_insync std::string m = primary; // You fill this in for Lab 7 // Keep synchronizing with primary until the synchronization succeeds, // or there is a commited viewchange bool ret = false; while(!ret && vid_insync == vid_commit) ret = statetransfer(m); ret = statetransferdone(m); return ret; } - rsm::statetransferdone 调用transferreq
bool rsm::statetransferdone(std::string m) { // You fill this in for Lab 7 // - Inform primary that this slave has synchronized for vid_insync pthread_mutex_unlock(&rsm_mutex); int r = 0; int ret = 0; handle h(m); rpcc *cl = h.safebind(); if (cl) { ret = cl->call(rsm_protocol::transferdonereq, cfg->myaddr(), vid_insync, r); } pthread_mutex_lock(&rsm_mutex); if (cl && ret == rsm_protocol::OK) return true; else return false; } - rsm::transferdonereq // 如果所有的backup全部recovery完毕,唤醒sync_with_backups()函数中等待的primary
rsm_protocol::status rsm::transferdonereq(std::string m, unsigned vid, int &) { int ret = rsm_protocol::OK; ScopedLock ml(&rsm_mutex); // You fill this in for Lab 7 // - Return BUSY if I am not insync, or if the slave is not synchronizing // for the same view with me // - Remove the slave from the list of unsynchronized backups // - Wake up recovery thread if all backups are synchronized if (insync == false || vid != vid_insync) return rsm_protocol::BUSY; for(typeof(backups.begin()) it = backups.begin(); it != backups.end(); ){ if (*it == m) it = backups.erase(it); else it++; } if (backups.empty()) pthread_cond_broadcast(&recovery_cond); return ret; }Step Four:Cope with Primary Failures
之是在在primary不变的情况下,处理backup(slaves, replicas…),现在遇到的情况是当primary失败后的情景。invoke函数了两个特殊的情况:
- 一个是当primary不再是primary时,返回NOPRIMARY的情况,这种情况下,client会调用init_members函数
cl->call(rsm_client_protocol::members, 0, new_view, rpcc::to(1000));,这个函数会返回一组新的集群信息,将返回vector的倒数第一个作为当前primary,再去请求。 - 第二个是当前的primary节点无返回信息,即当前primary失败。这是需要客户端在已知的view vector中取倒数第一个作为当前primary,再去请求。
step4 出现的这种primary失败的情况就体现出了我们lock server记录每一个client请求时最大值(xid)的意义了。当primary失效后,client和backup(slave)都不知道上一个请求到底有没有被处理(slave 无法知道 primary是在那个点宕机的)。如果处理了,而client以为没有处理,那么这就会导致duplicated request。加上对比某锁某用户的xid,如果比这次请求的xid小那么就是重复请求,新primary就会发现到。图[3]:
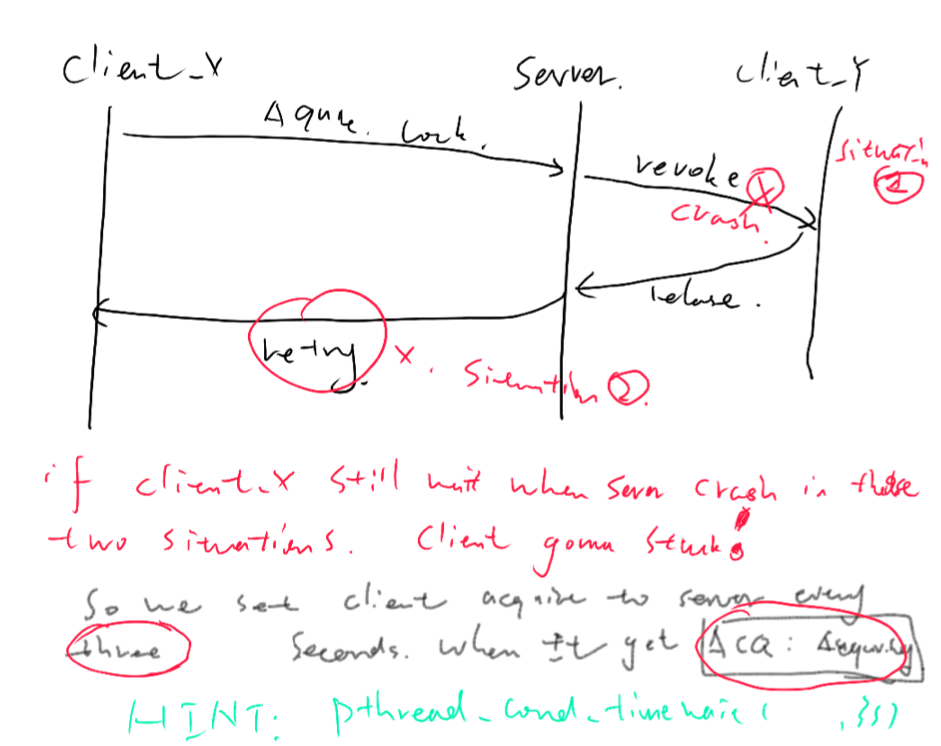
在图3中,在retry或者revoke时primary节点宕机,client_x处在等待的状况下,都会发生无法唤醒client_x的情况
还有一个点应当注意的是以下情况:当primary给一个client发送retry时,可能会在此时failure,新的primary也不会再给client发retry,这样这个client会在等待retry时停滞。这里解决的方法比较简单粗暴,就是每隔三秒就发一次,不管retry来没有来。
gettimeofday(&tp, NULL);
ts.tv_sec = tp.tv_sec + WAIT_TIMES;
ts.tv_nsec = tp.tv_usec * 1000;
ret = pthread_cond_timedwait(&lock_item.wait_acq_, &lock_map_mutex_, &ts);
if (ret == ETIMEDOUT) lock_item.is_retried = true;
这样,另一方的client也许会收到很多revoke的信息,即使当它已经不再拥有此锁。不过还好,有xid,我们可以判断这个lock到底应当怎样处理。
Step Five: Complicated Failures
此step没有需要做的一些实质性操作,在指定的位置加入breakponit 和 parition1 进行测试。需要测试./rsm_tester.pl 12 13 14 15 16
22 May 2018 by John Brown