分布式系统哈希分区处理问题
分布式系统哈希分区处理问题
分布式系统的存在,其重要的一个原因就是为了能够将负载很好的均摊到各个节点上,以数量优势提高性能,即分布式系统的可扩展性。大数据可以分布在多个主机的磁盘上,查询也可以有多个主机分别进行处理。分区的实现方式有很多种,目标基本一致,更好的将负载和查询均匀的分布在各个节点。如果分区不均匀(skew),那么会使此分区甚至整个系统的效率下降。这篇文章主要讨论在高负载下如何避免热点(hot spot)数据。
本文主要针对我工作中所接触的RTRec流式系统中所使用的分布式系统hash分区做讨论,并从架构的美学(aesthetics)提出一个相对简约分区处理系统。现有流式集群使用一致性哈希,主要有两个原因:
- 保证其负载均衡。这里指的是数据层面的负载均衡,因为接入层已经进行了负载均衡。
- 保证处理与查询的key落在同一台机器(节点)上。流式系统一个重要的工作就是收集客户端产生的上报数据做处理。如果要对某一个用户的行为进行上报,最高效的方法就是将这个用户的行为进行收集缓存,统计,入库。这些要求就要保证处理同一个用户的机器是相同的。同理,对APP信息的曝光,下载记录也需要同一key落在同一台机器上。
系统由三部分组成,zookeeper,WatchDog,节点集群。拓扑图如图[1]所示。节点之间的通讯通过一个全局的路由表作为路由,节点集群中的每个节点与zk相连。zk有两个作用,第一个作用是保持路由表的一致性,第二个作用监控集群中的每一个节点的状态。WatchDog的作用是针对现有节点集群做一致性哈希策略,即生成全局的路由表,将路由表放在zk上进行保管,一旦路由表有变化,通知集群中的各个节点去zk上更新最新的路由表。
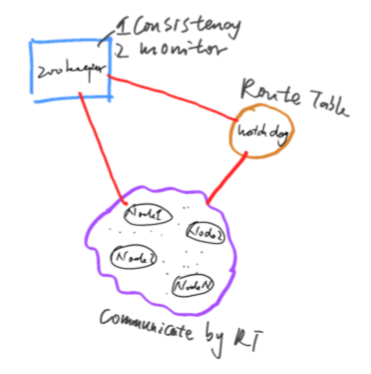
图[1]:流式系统框架
WatchDog生成一致性哈希的策略是将集群组成一个虚拟环状结构(传统的一致性哈希环),并固定分区数量。如果添加了一个节点,那么就从当前每个节点中抽取一些分区,做到再平衡。同理,如果某些节点被删除或者宕机,那么就将消失的节点以前负责的分区平摊到集群中现存的各个节点上图[2]。
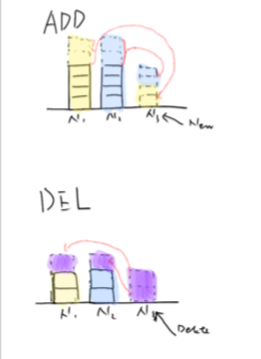
图[2]:当前采用的hash方式
这种哈希方式的优点是每次节点变动后的分区个数总能做到最优的平衡状态,分区的大小十分的均匀。但是这也带来了一个问题,必须需要一个WatchDog一样的角色为这个集群生成这张统一的哈希路由表。如果由每个节点自己生成,会由于节点变更的时序问题导致生成的哈希表不一致。图[3],这个例子说明了,相同的两个节点但顺序不同的变更状态导致了最终生成的路由表不同的例子。而且在分布式集群中,每个集群都需要一个WatchDog进行分配,WatchDog这一模式又回到了传统的server-client的集中式设计上,如果WatchDog宕机,就会导致整个集群无法更新路由表,严重时导致集群不能正常工作,可用性大大降低。如果给WatchDog一个备份,又回到了分布式系统一致性的问题上。总之WatchDog角色大大降低了整个分布式系统的可用性。
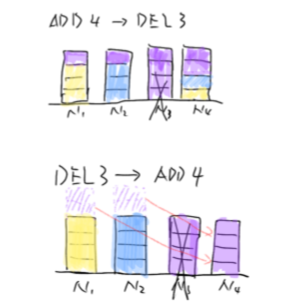
图[3]:当节点收到消息先后顺序不同时对哈希表的影响
在这里受到对象存储的启发,使用另一种一致性哈希方法。以去掉WatchDog,更好的保护此分布式系统可用性的角度出发,更充分的去中心化,充分利用zk的功能,采用哈希计算的策略保证系统的可用性与整体设计的简约。
具体方法:同样固定分区数量(BASE),每个节点在初始化时在zk创建临时(ephemeral)、自增计数(Sequence)节点,并订阅此目录。由zk生成的计数作为,每一个节点就获得到了一个全局唯一的ID。订阅的目的是,如果在某一订阅目录下有节点发生变动,会通知所有订阅的节点。每个节点内部采用虚拟节点(virtual_index)使得分布变得更加均匀。通过HASH(ID, virtual_index) mod BASE这一公式计算出每个节点所负责的分区。如图[4]的例子,每个节点较为均匀进行了分区。
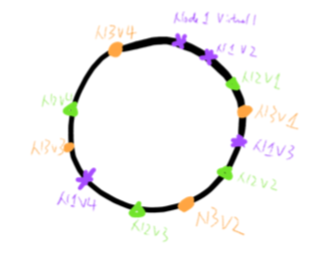
图[4]:使用计算生成的hash表在一致性哈希环上的分布
只要每一个节点使用的为同一个公式,那么所有节点自身生成的路由表都是相同的,不需要WatchDog这一角色进行统一生成分区表,因为路由表生成公式的计算与节点先后加入的顺序无关。其实与分布式文件系统类似,使用WatchDog就是文件存储,使用Hash函数映射分区就是对象存储。而WatchDog在文件系统中的角色就是元数据服务器,Hash函数映射作用就是类似ceph文件系统中的CRUSH。
在使用哈希计算这一方法进行分区时,需要考虑的一点就是哈希函数的计算公式与虚拟节点设置的个数。
- 哈希函数计算必须能够尽可能做到打散,一般使用MD5或者是SHA等这种优秀常见的方式。
- 虚拟节点的个数设置不易过少,如果过少,极有可能导致分局数量不均匀,从而不能做到很好的负载均衡。而虚拟节点也不是灵丹妙药,在固定的分区数量中,如果虚拟节点数越多那么在生成虚拟节点时,发生碰撞的概率也就越大,密码学中称为生日碰撞攻击,公式:
ε为碰撞概率,N为基数(base)大小,x为总虚拟节点个数
(这个公式是我用斯特林公式推倒出来,懒得化简。可能跟网上查出的生日碰撞格式有所出入,不过计算值是相同的),同时大量的虚拟节点增加了无用的计算量,浪费了生成路由表与节点间路由转发的时间与资源。图[5]为当分区个数设为4096,节点数为10时虚拟节点对系统的影响。橙色线条是节点虚拟个数与每个实体节点中所包含的分区数量方差的曲线图。蓝色为碰撞概率与虚拟节点数之间的关系曲线。可以看出,当每个分区的虚拟分区大于10个后,方差下降的幅度就很小了,在节点接近15个左右的时候,碰撞概率就达到90%了(密度已经很大了),再往上加虚拟节点造成的各种开销增大,而起到的作用很小,性价比极低。
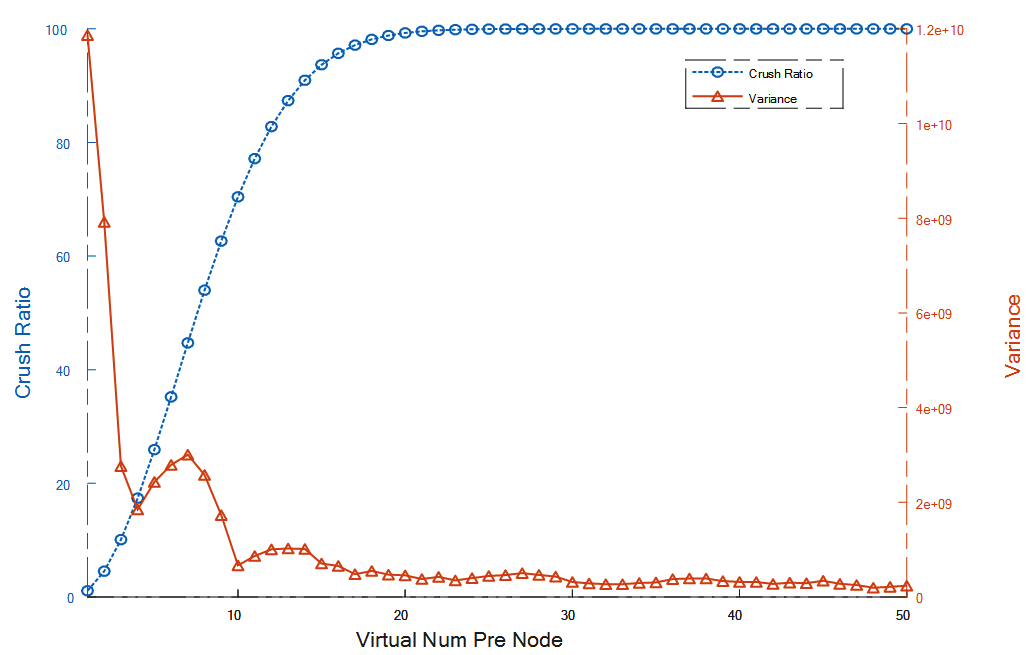
图[5]:虚拟个数与每个实体节点中所包含的分区数量方差的曲线图和碰撞概率与虚拟节点数之间的关系曲线图
从图中可以明显地得出在每个节点10个虚拟节点时起到的效果最好。
实验代码在github中获得(做实验时需安装zookeeper服务)
25 Jul 2018 by John Brown